大数据量化投资:研报文本挖掘选股策略
核心观点:
●借力研报,打造开放的量化选股模型
传统的多因子量化选股模型是封闭的,缺乏捕捉市场热点的能力,通过大数据技术,从财经媒体和分析师研报中捕捉热点和政策的变化,可以打造开放的量化选股模型。
分析师个股类研报每年大约5万份,相比财经媒体,分析师研报在专业度、可信度、规范度、实时度等方面有明显优势,是大数据量化投资的重要数据来源之一。
●热词库建设是构建量化选股模型的关键
通过对历史研报的统计,我们建立了基本面类、情绪面类、概念主题类三大热词库,其中基本面类和情绪类细分为正面词库和负面词库。我们统计了单个热词在近4年的选股效果,总体胜率比较高,相对沪深300有明显超额收益。
●“基本面+情绪面”热词库选股策略表现稳定
2011-2014年,策略相对沪深300、中证500的年化超额收益为21.29%、14.84%,月度胜率大约70%。
●“概念主题”热词库选股策略令人惊喜
以“油价下跌”和“一带一路”为例,截止12月19日,“油价下跌”热词概念股平均超额收益27.78%,“一带一路”热词概念股平均超额收益21.48%,其中表现最好的是中国交建,超额收益达93.28%、绝对收益达101.55%。
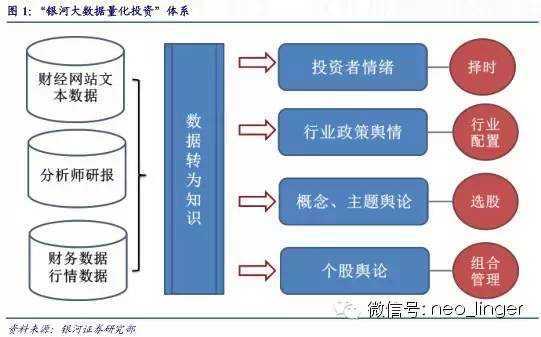
●“银河大数据量化投资”体系
我们将逐步建立起“银河大数据量化投资”体系,数据来源包括财经媒体、分析师研报、行情财务三大部分。我们认为,通过对投资者情绪、行业政策舆论、概念主题舆论和个股舆论进行大数据分析,可以构建择时、行业配置、选股和组合管理等量化投资模型。
传统的多因子量化选股模型是封闭的,缺乏捕捉市场热点的能力,通过大数据技术,从财经媒体和分析师研报中捕捉热点和政策的变化,可以打造开放的量化选股模型。
分析师个股类研报每年大约5万份,相比财经媒体,分析师研报在专业度、可信度、规范度、实时度等方面有明显优势,是大数据量化投资的重要数据来源之一。
一、银河大数据量化投资体系
近两年来,大数据和互联网金融发展迅猛,各大基金公司和券商纷纷加入大数据量化投资研究行列,甚至一些互联网公司已经布局,未来大数据量化投资研究将精彩纷呈。
国内已经有成功的案例,比如广发基金联合百度公司、中证指数公司开发百发100指数,南方基金则携手新浪财经、深证信息公司推出了i100指数和i300指数。
我们构建了银河大数据量化投资体系。理论上,大数据研究的引入,可以把量化投资各个领域重新建模,包括择时、行业配置、选股和组合管理等。
二、分析师研报是重要的数据来源
(一)信息的传导路径
传统的多因子量化选股模型依赖财报数据,其信息是非常滞后的,其封闭性让其无法跟上市场节奏,通过财经媒体和分析师研报,有助于量化选股模型捕捉到更加前沿的信息。

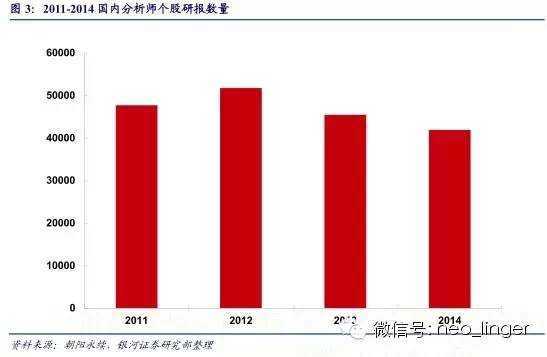
(二)分析师研报数量庞大
近4年来,个股类的分析师研报每年大约有5万分,是大数据量化投资的重要数据来源。
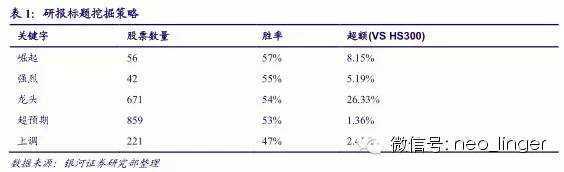
(三)简单的文本挖掘策略回顾
我们团队对分析师研报的应用有着深厚的积累。2013年我们推出了《事件投资,有效的研报标题关键字130521》。
该策略在 014年总体上还是有效的,但呈现一个特点,基本面相关的关键字效果在下降,而情绪类相关的关键字效果要更好一些。
简单的研报标题信息量非常有限,下文我们将进一步从研报摘要中挖掘更加有效、准确的信息。
三、文本挖掘技术介绍与热词库建设
首先,我们简单介绍一下文本挖掘的技术。
(一)VSM 模型与 LSA 模型
文本挖掘是信息挖掘的一个研究分支,用于基于文本信息的知识发现。文本挖掘利用智能算法,如神经网络、基于案例的推理、可能性推理等,并结合文字处理技术,分析大量的非结构化文本源,抽取或标记关键字概念、文字间的关系,并按照内容对文档进行分类,获取有用的知识和信息。文本挖掘涵盖了多种技术,包括数据挖掘技术、信息抽取、信息检索,机器学习、自然语言处理、计算语言学、统计数据分析、线性几何、概率理论甚至还有图论。
语义分析最经典的模型是向量空间模型(VSM:Vector Space Model)由 Salton 等人于20世纪70年代提出。它将文档表示成特征元素(主要是文档中出现的词语)的集合,即D(t1,t2,……tn)。最简单的计算词权重的方式是:如果词出现在文档中,则权值为1;没有出现,则权值为0。这种方法的缺点在于,它没有体现词语在文档中出现的频率。
VSM 模型的基本概念包括:
文档(document): 通常是文章中具有一定规模的字符串。文档通常我们也叫文本。
特征项 (feature term):是VSM中最小的不可分的语言单元,可以是字、词、词组、短语等。一个文档内容可以被看成是它含有的特征项的集合。表示为一个向量:(t1,t2,……tn),其中it是特征项。
特征项权重 (term weight): 对于含有n个特征项的文档(t1,t2,……tn),,每一个特征项ti都依据一定的原则被赋予了一个权重ωi,表示该特征项在文档中的重要程度。这样一个文档D可用它含有的特征项及其特征项所对应的权重所表示:D=(ωi,t2=……ω2,tn=ωn),简记为D(ω1,ω2,……ωn),其中ωi就是特征项it的权重。
1990 年,Deerwester 等人于提出了潜在语义分析(LatentSemanticAnalysis)模型,用于挖掘文档与词语之间隐含的潜在语义关联。LSA的理论基础是数学中的奇异值矩阵分解(SVD)技术。LSA(latentsemantic analysis)潜在语义分析,也被称为 LSI(latent semanticindex)。该方法和传统向量空间模型(vectorspacemodel)一样使用向量来表示词(terms)和文档(documents),并通过向量间的关系(如夹角)来判断词及文档间的关系,不同的是,LSA将词和文档映射到潜在语义空间,从而去除了原始向量空间中的一些“噪音”,提高了信息检索的精确度。
关于模型更多的细节可以参考专业的学术论文,在此不展开论述。
(二)热词库建设是构建量化选股模型的关键
文本挖掘的技术已经日臻成熟,互联网类的公司有非常成熟的技术,那么在证券领域如何运用呢?热词库的建设是关键,我们认为,无论是财经媒体的文本挖掘还是分析师研报的文本挖掘,都依赖于热词库的积累。
我们把词库建设分成三类:基本面类、情绪面类和概念主题类。
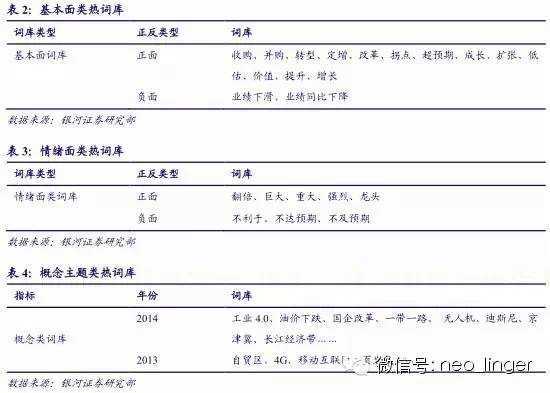
(三)基本面、情绪热词效果分析
研报摘要反应了研报的核心内容,大券商分析师的研报摘要表述清晰、简洁、准确,通过对研报摘要文本挖掘提炼关键信息,可以起到事半功倍的效果。后文的热词挖掘都是针对研报摘要进行。
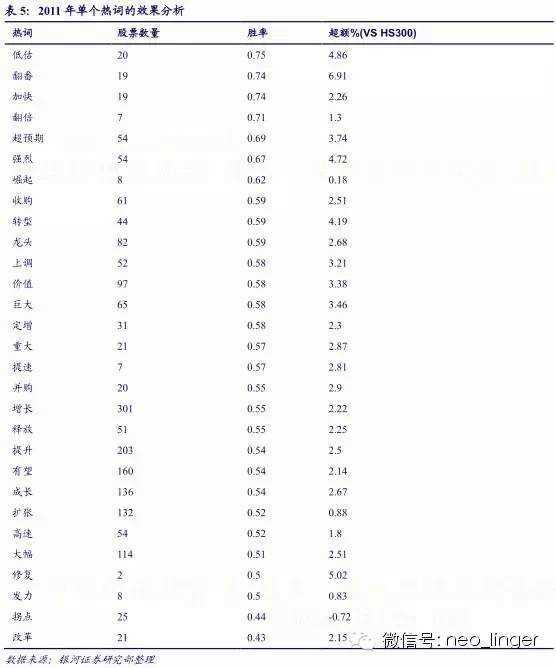
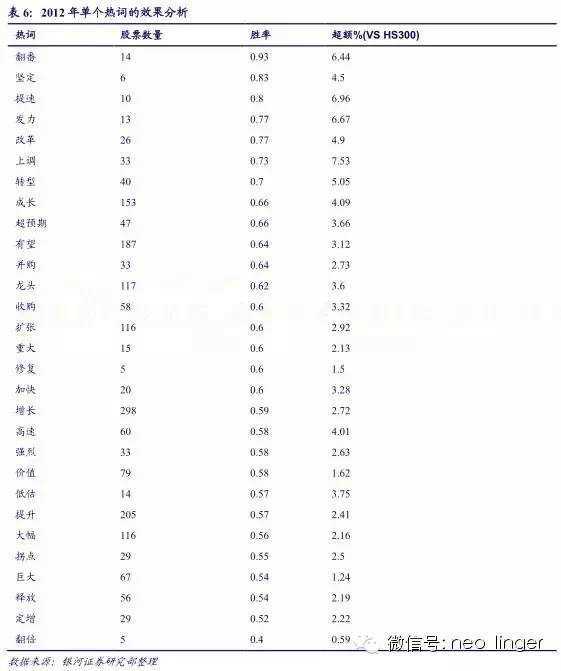
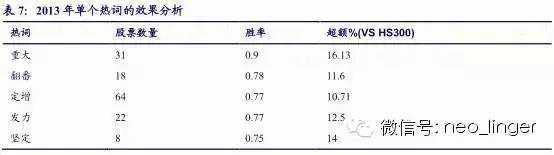
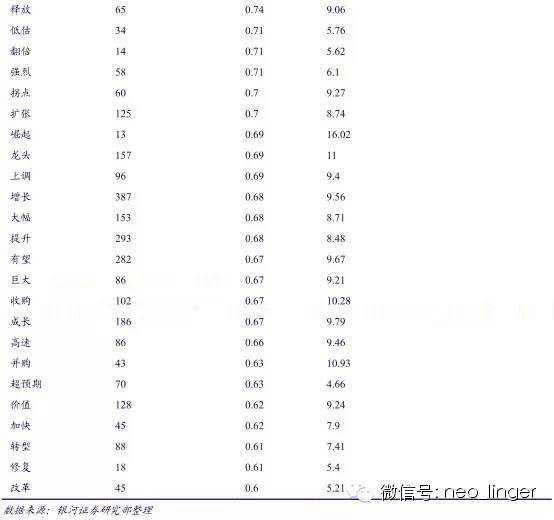
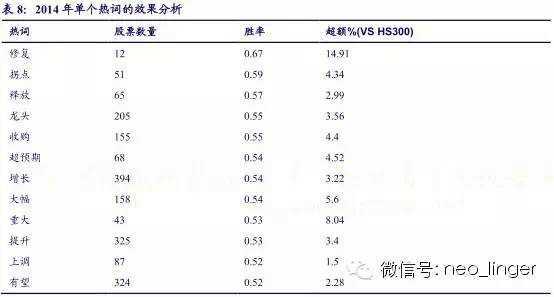

从热词在 2011-2014年的表现来看,单个热词是不稳定的,但热词库整体的胜率和超额是比较好的,因此,我们用整个热词库构建量化选股模型。
四、“基本面+情绪面”热词库选股策略
(一)策略净值
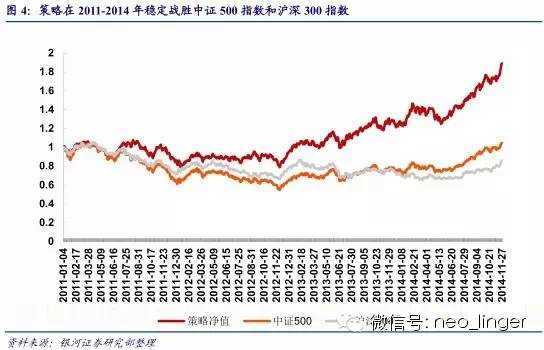
对研报标题和摘要进行文本挖掘,通过基本面热词库、情绪面热词库两个角度进行筛选,成分股持仓30个交易日,每5个交易日滚动调仓一次,双边手续费取千分五,策略净值如图4 所示,可见,策略能够稳定战胜中证500指数和沪深300指数。
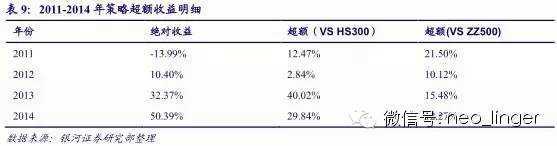
策略每年的超额收益是比较稳定的,如表 9 所示。
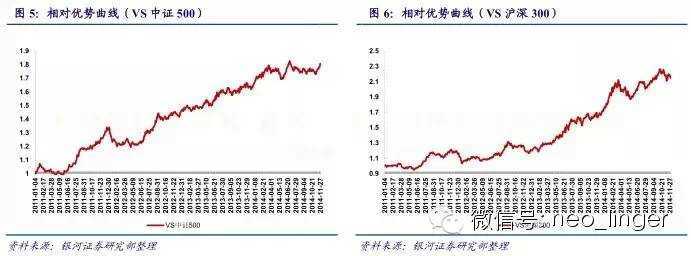
(二)相对优势分析
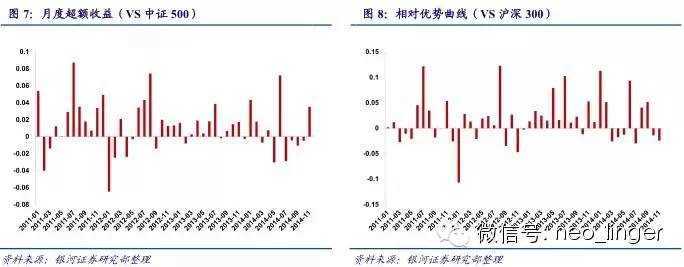
(三)案例分析
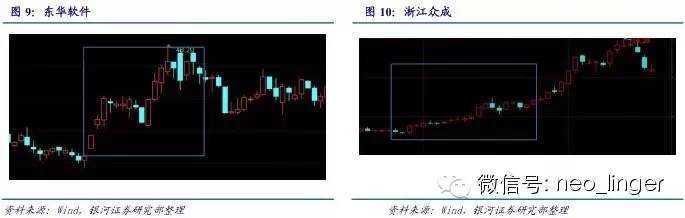
东华软件在2014年的第一份研究报告是《东华软件-002065-前瞻布局,再创优势-140122》,改报告出现的热词有:并购、龙头、加速、增长、提升等,符合热词库选股条件,之后的一个月内,股价大幅上升。
2014年8月 24日,某分析师发布《浙江众成-002522-公司深度研究:募投项目及新品投放,业绩望迎来拐点-140824》,研报中出现的热词有:翻番、拐点、超预期等,符合热词库选股条件,之后的一个月内,股价大幅上升。
五、“概念主题”热词库选股策略
除了“基本面+情绪面”两个热词库筛选之外,我们增加第三类热词库的筛选——“概念主题”,打破了传统多因子量化选股模型的封闭性,有利于量化模型捕捉市场热点和政策的变化。
以当前最热门的两个概念——“油价下跌”和“一带一路”为例,我们统计了入选成分股的表现。
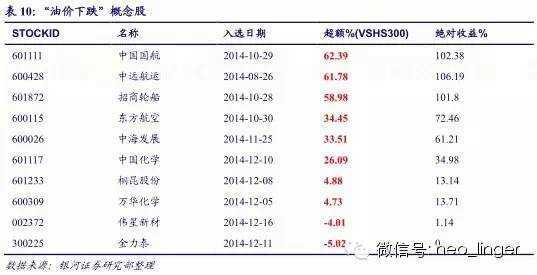
(一) “油价下跌”概念
截止2014年12月19日,入选成分股相对沪深300平均超额收益为27.78%。
(二) “一带一路”概念
截止2014年12月19日,入选成分股相对沪深300平均超额收益为21.48%。
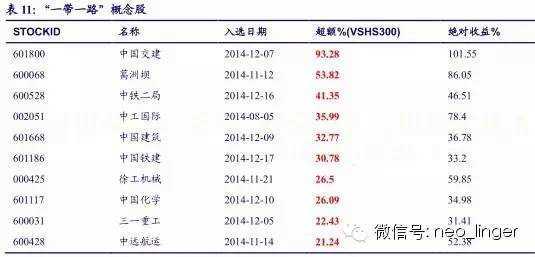
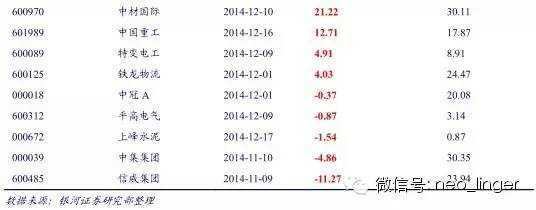
(三) 案例分析:中国交建
2014年12月7日,银河证券分析师发布报告《中国交建-601800-公司跟踪报告:一带一路龙头,五商中交再造国际工程霸业-141207》,研报中出现“一带一路”、“国企改革”等概念,并出现多个“增长”、“提升”、“快速”、“成长”、“龙头”等热词,符合我们的选股条件。截止12月19日,股价已经上涨101.55%,相对沪深300超额收益达93.28%。
六、风险提示
本报告中的所有模型都是根据历史数据建立和测算的,图表中展示的效果亦是基于历史数据,并不必然保证未来有同样好的收益。本报告中的所有模型和结论只供投资者参考,并不能完全排除未来的风险。
作者:温尚清/银河证券
交易技术, 交易策略
风险提示及免责条款
市场有风险,投资需谨慎。本文不构成个人投资建议,也未考虑到个别用户特殊的投资目标、财务状况或需要。用户应考虑本文中的任何意见、观点或结论是否符合其特定状况。据此投资,责任自负。本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
