Google披露:大规模集群管理工具Borg的细节
摘自:InforQ
微信号:inforqchina
Google最近发布了一篇名为“Google使用Borg进行大规模集群的管理”的论文,披露了这个在过去极少提及的技术的细节。
Borg是一个集群管理器,它负责对来自于几千个应用程序所提交的job进行接收、调试、启动、停止、重启和监控,这些job将用于不同的服务,运行在不同数量的集群中,每个集群各自都可包含最多几万台服务器。Borg的目的是让开发者能够不必操心资源管理的问题,让他们专注于自己的工作,并且做到跨多个数据中心的资源利用率最大化。下面这张图表描述了Borg的主要架构:
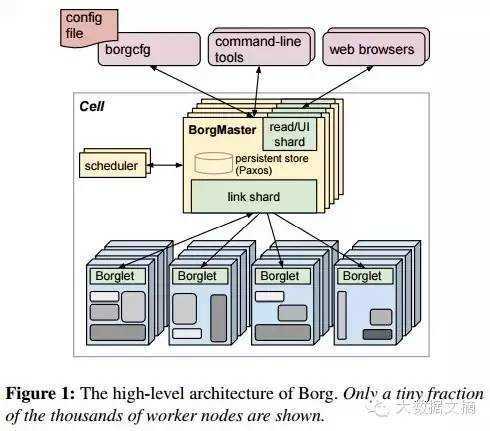
Borg的高级别架构图,其中只展示了全部几千个工作节点中很少的一部分
这套架构中包含了以下组件:
单元(Cell):将多个机器的集合视为一个单元。单元通常包括1万台服务器,但如果有必要的话也可以增加这个数字,它们各自具有不同的CPU、内存、磁盘容量等等。
集群:一般来说包含了一个大型单元,有时也会包含一些用于特定目的的小单元,其中有些单元可以用做测试。一个集群通常来说限制在一个数据中心大楼里,集群中的所有机器都是通过高性能的网络进行连接的。一个网站可以包含多个大楼和集群。
Job:是一种在单元的边界之内进行执行的活动。这些job可以附加一些需求信息,例如CPU、OS、公开的IP等等。Job之间可以互相通信,用户或监控job也可以通过RPC方式向某个job发送命令。
Task:一个job可以一个或多个任务组成,这些任务在同一个可执行进行中运行。这些任务通常是直接在硬件上运行的,而不是在虚拟环境中运行,以避免虚拟化的成本。任务的程序是静态链接的,以避免在运行时进行动态链接。
分配额(alloc):专门为一个或多个任务所保留的机器资源集。分配额能够与运行于其上的任务一起被转移到一个不同的机器上。一个分配额集表示为某个job保留的资源,并且分布在多台机器上。
Borglet:一个运行在每台机器上的代理。
Borgmaster:一个控制器进程,它在单元的级别上运行,并保存着所有Borglet上的状态数据。Borgmaster将job发送到某个队列中以执行。Borgmaster和它的数据将会进行五次复制,数据将被持久化在一个Paxos存储系统中。所有的Borgmaster中有一个领导者。
调度器:对队列进行监控,并根据每个机器的可用资源情况对job进行调度。
Borg系统的使用者将向系统提交包含了一个或多个任务的job,这些任务将共享同样的二进制代码,并在一个单元中进行执行,每个Borg单元由多台机器组成。在这些单元中,Borg会组合两种类型的活动:一种是例如Gmail、GDocs、BigTable之类的长期运行服务,这些服务的响应延迟很短,最多几百毫秒。另一种是批量处理的job,它们无须对请求进行即时响应,运行的时间也可能会很长,甚至是几天。第一种类型的job被称为prod job(即生产job),它们相对于批量job来说优先级更高,后者被认为非生产环境中的job。生产job能够获得一个单元的CPU资源中的70%,并且占用所有CPU数量的大约60%,它们还能够分配到55%的内存,并占用其中的大约85%。按照Google的研究员John Wilkes所说:在单元中混合不同类型的job,目的在于尽可能地优化资源的使用情况,能够节约Google在整个数据中心上的成本 。
根据论文中所写的内容,某些单元的任务量是每分钟接受1万个新的任务,而一个Borgmaster能够使用10到14个CPU内核,以及50GB的内存。一个borgmaster能够实现99.99%的可用性,但即使某个borgmaster或borglet出现停机状况,任务也能够继续运行。有50%的机器会运行9个或9个以上的任务,而某些机器能够在4500个线程中运行25个任务。任务的启动延迟平均时间是25秒,其中的20秒用于安装包。这些等待时间中的大部分都与磁盘访问有关。
这套系统的主要安全机制是Linux chroot jail以及ssh,通过borglet进行任务调试的工作。对于运行在GAE或GCE中的外部软件,Google将使用托管的虚拟机,作为一个Borg任务在某个KVM进程中运行。
Google还有一个名为Omega的集群管理器,这里简单地描述一下Omega:
Omega支持多个并行的、特定的“垂直任务”,其中每一个垂直任务基本类似于一个Borgmaster,只是缺少了持久化存储与连接分片的功能。Omega的调度器使用了优化的并发控制,对于储存在某个中央持久化储存系统中的单元状态的理想情况与观察到的情况进行操控,这个调度器通过一个独立的连接组件与Borglet进行双向同步。设计Omega架构的目的是为了支持多种不同的工作任务,每一种都有自己的应用程序特定RPC接口,状态机,以及调度策略(比方说,长时间运行服务器、来自于不同框架的批量job,例如集群储存系统之类的基础设施服务,以及Google云平台上的虚拟机)。
另一方面,Borg提供了一种“适合所有情况”的RPC接口、状态机机制以及调度器的策略,它们的规模与复杂度随着时间的推移都在不断地增长,其原因是它需要支持多种不同的工作任务。目前来说它的伸缩性还没有遇到什么问题。
Google在过去十年间在生产环境上所学到的某些经验与教训已经应用在Kubernetes的设计上:对属于同一服务的job的操控能力、一台机器多个IP地址、使用某种简化的job配置机制、使用pods(其作用与分配额相同)、负载均衡、深度反思为用户提供调试数据的方式。参加了Borg项目的许多工程师目前也参与了Kubernetes这个项目的研发。
数据分析, 数据挖掘, job, borg
风险提示及免责条款
市场有风险,投资需谨慎。本文不构成个人投资建议,也未考虑到个别用户特殊的投资目标、财务状况或需要。用户应考虑本文中的任何意见、观点或结论是否符合其特定状况。据此投资,责任自负。本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
