如何1分钟直观理解一个数理概念?
“1分钟直观理解一个数理概念”(Maths in a minute)是 Plus Magazine 推出的一个系列,用短小的篇幅直观解释一些常见数理概念的内涵。那么,今天要给大家分享的是——对称性、期望、热力学第二定律、布尔代数和中心极限定理。
对称性(Symmetry)
在直觉上,我们都知道什么是对称性,但是通过语言来描述什么是对称性却比我们想象的还要困难。下面这张蝴蝶的图片是对称的,是因为即使图片沿着中心轴线翻转,蝴蝶仍然能够保持原样。我们知道正方形是对称的,是因为它绕着中心旋转90度,或者分别沿着水平、垂直或对角轴线翻转之后,都能保持不变。如果一幅图片经过某种变换(比如旋转或者对映操作)后仍然保持不变,那么这幅图片就是对称的。或者更一般地讲,对称就是保持不变性。

如同蝴蝶,公式也具有对称性。
以上关于对称的定义,也可以拓展到图片以外的其他事物身上。比如,不管是x还是-x都会使数学表达式x^2得出相同的结果,所以x^2在x到-x的变换下是对称的。
如果你要制定学校的课程时间表,而此时有两位能够做相同工作的老师,他们的可工作时间也相等,那么在这两位老师轮流排班的变换下,制定时间表的问题就具有了对称性:如果你有一个排班办法,那么对换两位老师也能得到另一个解决方案。
在物理学上,我们知道不管是在伦敦还是在纽约,运动定律都完全相同,也就是说这些定律在空间变换下是对称的。
因此,公式、问题、甚至自然规律都能够展现出对称性。对称性在物理中是一个非常重要的概念:物理学家相信大自然的基本规律都应具有某种对称性,他们在建立理论的一开始就纳入了对称性,哪怕彼时甚至还没有观测到任何有关其对称性的直接证据。当涉及到现实生活问题时,对称性也会展现出实用的一面,就像上述老师例子所表明的:如果你了解了问题的对称性,就能立刻通过一个解决方案而知道其他的解决方案。
在我们日常生活中,对称性也扮演着一个有趣的角色。有些人表示对称性是美的先决条件:我们只会认为对称的人是美的,因为不对称可能标志着疾病或是其它缺陷;而另一方面,有时候对称性的缺失却因与众不同而具有吸引力:我们都遇见过性感的斜视或者歪着脸的微笑。无论你对于对称性有何见解,对称性都绝不仅是一个抽象的数学概念。

效力于多特蒙德的德国球星马尔科·罗伊斯(Marco Reus)。
他嘴歪歪的,但粉丝可不会因为他嘴是歪的就觉得他不帅了。
期望(Expectation)
如果公平地掷骰子,你掷出1到6这六个数字的几率都是相同的。然而掷骰子的期望值(expected value)却是3.5。这怎么可能?骰子上根本就没有这个数字嘛!
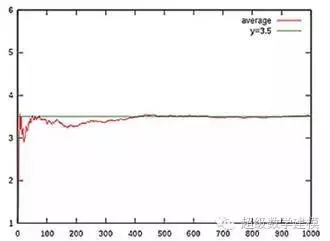
图片表示掷骰子结果(红色线)的平均值如何
随着投掷的次数增加而收敛于期望值3.5(绿色线)。
于是,对n次投掷的结果求平均,得到的数字大约等于
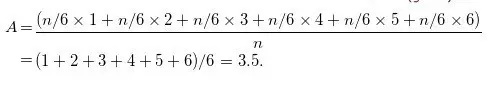
强大数定理(the strong law of large numbers)表明,当n的值越大,实际平均值就越接近3.5。就某种意义而言,3.5这个数字是掷无穷多次骰子所得的平均值。
假设掷骰子的过程并不公平,那六个数出现的几率会不尽相同。再假设出现一次1的概率是p1,2的概率是p2,等等以此类推。于是,大数n次投掷结果的平均值约为
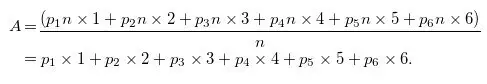
这就是广义的期望所蕴含的思想。如果一个随机变量(random variable)有X1至Xm的m种可能结果,相应的概率是p1至pm,那么结果的期望值就是
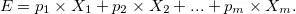
热力学第二定律(the second law of thermodynamics)
同事和我们在同一间办公室办公,他偶尔会对我们杂乱的办公桌面感到绝望,然后替我们收拾整洁。整理之后的桌面非常有序,用物理学语言来描述这个状态就是低熵(entropy)。
熵是描述物理系统无序程度的量。正如同事从个人经验中所知,每当我们出现在办公室里,桌面就会变得越来越杂乱,桌面的熵一定会增加。这实质上可以归结为一个概率论证——整洁的桌面总是相似的,脏乱的桌面各有各的脏乱,因此,桌子进入脏乱状态的概率总比进入整洁状态的概率大。除非有人干预并主动整理(这可不是我们的强项),否则熵一定会增加。

这肯定不是你球后台办公桌的桌面,嗯
这真的不是我们的错——总不能与物理定律做斗争吧,而且这还是最基本的物理定律之一:热力学第二定律(the second law of thermodynamics)。这条定律的内容是,孤立系统的熵永不减少。这不仅解释了为什么桌面永远不会自行整洁,还解释了饮料中的冰块为什么熔化。所有系统都会演化至最大熵状态:与高度结构化的冰块在温热的液体组成的系统相比,冰块完全融化,再和饮料充分混合的系统显然本质上更为混乱。系统熵最高的状态也正是平衡态。
热力学第二定律的概念来自统计力学领域。统计力学是通过统计学原理描述大量粒子行为的理论,显然,这对于描述气体或液体的行为很有用——气体和液体就是由大量粒子组合而成的嘛。我们可以尝试写出(或者用计算机模拟出)描述每个气体粒子运动和所有相互作用的牛顿方程,但这样做就太笨了,而且根本无法实现:一升空气中有大约3x1022个分子,每一个分子都需要大量公式来描述,更不说分子间的相互作用了。于是,物理学家想出了一个办法,可以不通过一一描述每个粒子来描述系统,而是运用统计学来预言整个系统的集体行为。
比如,在一间屋子里揭开一个充满气体的瓶子的瓶盖,直觉告诉我们气体不会继续乖乖待在瓶子里,而是会逐渐扩散直至占满整个空间。在屋中气体分子所有可能的排列方式中,仅有少数方式是所有气体留在敞口的瓶子里,而气体分子扩散到整个盒子的排列方式远多于此。气体分子总是散开,不会返回瓶子里,这件事并不是百分百一定发生的,但它是最有可能发生的。
像热力学第二定律这样的基本的自然定律,其基础竟然是统计上的可能性,这件事乍一看很奇怪——毕竟一般定律都是描述确定性的,但“可能性”却蕴含了不确定性。
法国数学家埃米尔·博雷尔(Émile Borel)借用了一个有趣的比喻来说明这条定律的不可违背性:假如一百万只猴子每天打字十小时并连续打一年,将它们打出的字组合起来,在世界上藏书最丰富的图书馆也找不到和它们打出的字符序列完全重合的内容,而违背统计力学定律的可能性则要更低。“当数字很大时,偶然性是必然性最好的保障。幸运的是,在大量分子、能量以及辐射组成的研究中,我们应对的都是无比庞大的群体,从而从中得到确定性,这份确定性,同祈求幸运女神垂青的‘可能性’可不一样。”英国物理学家亚瑟·爱丁顿(Arthur Eddington)写下的这段话,很好地捕捉到了偶然与必然之间的奇特关联。
布尔代数(Boolean algebra)
只要你使用电脑,你就离不开布尔逻辑(Boolean logic)。以英国数学家乔治·布尔(George Boole)命名的布尔逻辑在计算机发明的很久之前就已经建立了。在布尔逻辑体系下,一个语句可以是真的或者假的(例如此刻“我想要一杯茶”是假的,而“我想要块蛋糕”却总是真的),并且这些语句可以通过“与(AND)”,“或(OR)”,和“非(NOT)”来连接。要证实这些复合语句是真是假,需要做一个真值表(truth table),列出基础语句能够取得的所有可能值,进而列出复合语句能够相应取得的所有值。
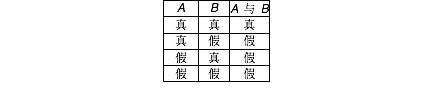
表示“A与B”所有可能取值的一个简单的真值表
对于简单的逻辑语句来说,真值表是实用的,但是对于更复杂的语句,真值表就会变得繁琐恼人,而且更易出错。布尔解决了这个难题,他机智地意识到,二进制逻辑运算的方式与我们普通算术运算明显相似,除了有少量的差别。
在这种称为布尔代数(Boolean algebra)的新算术体系中,变量是逻辑语句(粗略地讲,就是真或假的句子)。这些语句只能取两个值,对于我们知道是假的语句取为0,真语句则取为1。
于是我们可以将“或”重新写为只用0和1表示的一种加法:
0 + 0 = 0 (因为“假或假”仍为假)
1 + 0 = 0 + 1 = 1 (因为“真或假”以及“假或真”均为真)
1 + 1 = 1(因为“真或真”仍为真)。
也可以将“与”重新写为一种乘法:
0 × 1 = 1 × 0 = 0 (因为“假与真”以及“真与假”均为假)
0 × 0 = 0 (因为“假与假”仍为假)
1 × 1 = 1 (因为“真与真”仍为真)。
因为变量只能取0或1,所以我们可以将“非”运算定义为补运算,也就是取变量的补集:
如果A=1,那么非A=0
如果A=0,那么非A=1
A + 非A = 1 (因为“真或假”为真)
A × 非A = 0 (因为“真与假”为假)。
这些新定义的运算在很大程度上与我们熟知的加法和乘法的概念相似,但是它们仍然存在关键的区别。在布尔代数中,公式的部分项可以很容易消除,这一点很方便实用。例如,在A + A × B中,不管B取什么值或是该式表达了什么逻辑语句,变量B的存在都对结果没有任何影响。这是因为如果A为真(等价于A=1),那么无论B是否为真,A或(A与B)都为真;如果A为假(即A=0),那么无论B为何值,A或(A与B)都为假。所以布尔代数给予了一种简化:表达式A + A × B等于一个简单的A,即A + A × B=A。
除此之外,布尔代数还有一种在加法和乘法间的逆对偶性:
(A + B)' = A' × B'
(A x B)' = A' + B'。
这正是德摩根定律(De Morgan’s Laws),因英国数学家奥古斯塔斯·德摩根(Augustus de Morgan,1806-1871)命名。(可以确信的是在使用等效真值表时上述等式同样成立。)
这两条定律,就是布尔代数在简化复杂逻辑语句过程中的两条诀窍。到头来,还是要感谢发明布尔代数的乔治这位老兄!
中心极限定理(the central limit theorem)
统计学的中心思想是通过观察小样本即可得到整个群体的信息。如果没有这个思想,就不会有民意调查或是选举预测,也没有办法测试新药品或者桥梁的安全性,等等。我们能够做到这类事情,并把不确定性控制在一个范围里,很大程度上多亏了有中心极限定理。

人口的平均体重是多少?
为了了解中心极限定理如何运作,假设你想要得到全国人口的平均体重。你需要出门随机选择100个人,测量他们的体重,然后计算出平均值——称为样本平均(sample average)。样本平均应该能够提供一些关于全国平均体重的信息。但是,如果你挑选的样本恰好都是大块头,或者都是骨瘦如柴的人,情况会如何呢?
为了了解样本平均的代表性如何,你需要知道100人样本的平均体重会与群体平均值相差多少:假如你取了很多个容量为100人的样本,分别算出平均体重,那么这组数字会如何变动?以及该组数字的平均值(样本平均的平均值)与总群体真实的平均体重比较结果如何?
比如说,假设你发现如果获取大量的100人样本,记下每个样本的平均体重,最终得到的数值等可能地分布于10千克至300千克间,那么由此可知,通过单个容量为100的样本来估算总体平均并不是一个好的方法,因为不确定因素太多。你会得到10千克至300千克间任何可能的值,但并不知道哪一个最接近群体真实的平均体重。
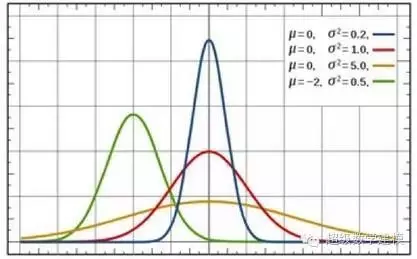
不同平均数和方差的正态分布。
如此一来,当我们对总群体的体重分布一无所知时,如何得出100人样本平均的分布(也叫抽样分布)呢?这正是中心极限定理发挥作用的地方:对于足够大的样本,抽样分布近似于正态分布,也就是著名的钟形分布曲线——来近似。(通常认为,样本容量达到30就足够了。)
正态分布的平均数(也就是样本平均的平均值,即钟形曲线顶部的位置)与群体的平均值(群体平均体重)相同。正态分布的方差(即平均数的变化幅度,由钟形的宽度表示)则由样本容量决定:样本越大,方差越小。两者之间的确切关系可由公式给出。
如果样本容量足够大(100要比30大很多,所以肯定足够),样本正态分布的方差就相对较小,意味着观测的平均体重与正态分布的平均数相近(因为钟形非常窄长)。又因为该正态分布的平均数等于群体真实的平均体重,所以对于真实平均值来说,观测平均值是个很好的近似。
所有这些都可以用数学语言精确地描述。比如,你可以准确地表明,有百分之多少的信心确信真实平均值与样本平均值的差距在某个值以内,还可以用观测结果计算出需要多大的样本才能得到给定精度的估计。中心极限定理给统计推论的艺术赋予了精确度,也正是这一定理使得正态分布无处不在。
理论基础, 样本, 对称, 定律
风险提示及免责条款
市场有风险,投资需谨慎。本文不构成个人投资建议,也未考虑到个别用户特殊的投资目标、财务状况或需要。用户应考虑本文中的任何意见、观点或结论是否符合其特定状况。据此投资,责任自负。本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
