深度学习开发环境调查结果公布,你的配置是这样吗?(附新环境配置)
本周一(6 月 19 日)机器之心发表文章《 我的深度学习开发环境详解:TensorFlow + Docker + PyCharm 等,你的呢(附问卷) 》介绍了研究员 Killian 的深度学习开发环境:TensorFlow + Docker + PyCharm + OSX Fuse + Tensorboard,并附了一份调查问卷想要了解机器之心读者配置的开发环境、对编程语言、框架的使用情况。虽然获得的反馈量比较有限,但我们也观察到了一些比较有趣的现象。在这篇文章中,我们将对此问卷的结果进行介绍,希望对需要配置开发环境的读者有所帮助。最后,我们介绍了一种新的开发环境配置:Jupyter + Tensorflow + Nvidia GPU + Docker + Google Compute Engine。_
问卷结果
该调查问卷文章发布之后共有超过 10800 名读者阅读,收到大量有效答卷,另有 16 名读者是以留言的方式在文章下介绍了自己的开发系统。大部分被调查者来自中国大陆,此外还有多名来自北美大学和研究机构的调查者参与其中。以下的数据统计图表中,并不包含微信文章留言的数据。
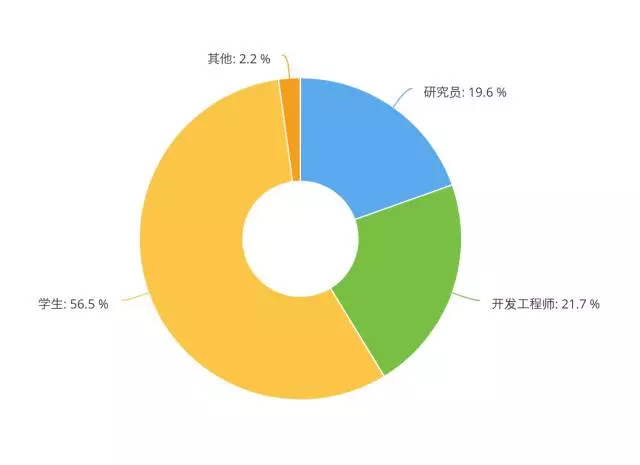
根据表单后台的数据统计,参与调查的读者中大部分为学生,然后是开发工程师、研究员、产品经理等。
而在被调查者的研究方向上,计算机视觉领域占比接近一半(48.2%),自然语言处理次之(26.8%),这部分反映了目前深度学习的主要研究方向。此外还包括金融风控、数据分析、现场安全识别、通信、时空大数据、医学图像、催化以及材料模拟等领域。

下面就开始详细为大家介绍调查者们最常用的编程语言、深度学习框架,以及在开发过程中面临的难题。
一、Python 成为深度学习主流语言
机器之心一直关注机器学习研究员、工程师在开发过程中所注重实用的工具、语言。在不久之前发布的文章《[业界 | 超越 R,Python 成为最受欢迎的机器学习语言](http://mp.weixin.qq.com/s?__biz=MzA3MzI4MjgzMw==&mid=2650720220&idx=3&sn=c3b8b65ec118d6fdef3f55e5f29e89ff&chksm=871b03a2b06c8ab4b0a0c87a3b3647372578b129ad5f420fddc5a1a84138a7db51911e143980&scene=21# wechat_redirect)》中,KDnuggets 与 O'Reilly 的调查结果都表明,越来越多的人开始使用 Python 进行机器学习。
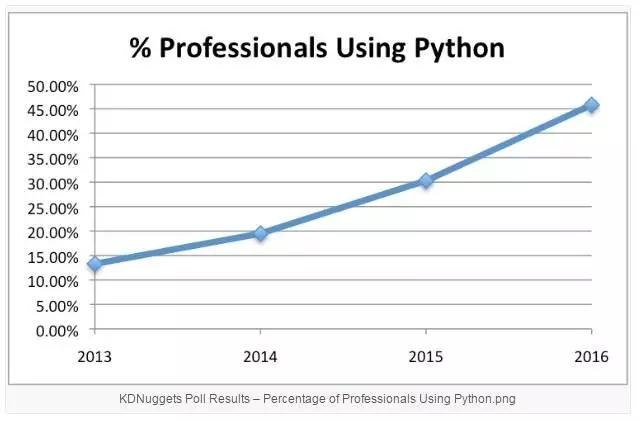
2016 年 KDNuggets 调查结果
在机器之心问卷中,对于问题「您认为哪种语言会成为深度学习的主流语言?」,所有被调查者的态度完全一致:Python!看来,Python 已是绝大多数从业人员必须学习的语言,同时也是众望所归的未来主流深度学习语言。
O'Reilly 2016 年度数据科学薪资调查曾显示:Python 和 Spark 是最对薪资有贡献的工具。Python 具有开发速度快的特点,Caffe、TensorFlow 等主流深度学习框架都对其支持。腾讯最近推出的机器学习高性能计算平台 Angel 在支持 Java、Scala 之外,也将在未来对 Python 提供支持。
在机器之心的问卷中,调查者反馈,虽然他们会使用其他编程语言,比如 R、C++,但实际运行程序的编写还是主要使用 Python,简单、开发速度快是很大的优势。
其他语言的使用情况简介如下:Matlab 用于快速完整、可视化研究;R 方便框架模型的验证分析,也便于处理数据和画图。因此,多数人在不同的开发流程中使用不同的语言。
二、TensorFlow 占据半壁江山
而在框架方面,谷歌支持的 TensorFlow 就没有这样的垄断地位了,不过它也已占据了接近一半(48%)的水平。完善的功能和大量的支持文档(众多 TensorFlow 支持者提到的)是目前 TensorFlow 的强项,存在于 GitHub 中的大量实现更是不容忽视,可视化工具 TensorBoard 则为开发者提供了直观的引导。但由于网络问题,TensorFlow 系统在大陆的搭建是个难题。部分被调查者也指出,TensorFlow 的 Windows 支持也为他们带来了便利。
Facebook 新近推出的框架 PyTorch 人气急剧攀升,在仅仅推出 5 个月的情况下达到了第二的位置(16%),因支持动态计算图,易用性和强大的性能而出名。在业界还需要产品迁移的情况下,学界已经出现拥抱 PyTorch 的趋势了。
同属于 Facebook 的 Caffe/Caffe2 则占据第三(14.7%),大部分被调查者在对于 Caffe 系列的评价中都提到了快速的特点。
此外,亚马逊支持的 MXNet 占据了 10.7% 的用户数量,排名第四。被调查者认为,MXNet 拥有很好的社区支持,因而易于使用。
三、硬件
硬件方面,超过一半的被调查者明确表示自己的深度学习硬件是英特尔 Core i7 + 英伟达 Geforce GTX 1080(Ti)的组合。与 TitanX 相比,英伟达 Tesla 系列的应用显得更少,看来英伟达推动的商用机器学习计算卡仍然需要进一步的推广。由于资源限制,GPU 阵列的使用并不流行,而云服务也没有被大部分开发者采用(也是经费原因)。
目前,虽然人们对于多 GPU/分布式机器学习训练/处理的呼声很高,但相关的教程和可以借鉴的方法仍显欠缺,这或许是经费之外人们面临的最大难题。
四、系统
Linux 显然是深度学习的必备系统,虽然 TensorFlow 已有 Windows 支持,但大多数受访者表示自己的深度学习机器使用基于 Linux 的 Ubuntu 系统。
五、面临的难题
在搭建深度学习环境的过程中,各组件的兼容性问题一直是困扰开发者们的难题,部分开发者表示依赖关系处理比较头疼,而使用 Docker 可以部分解决这些问题。英伟达的 cuda/GPU 驱动程序安装困难也是很多调查者提到的问题。
需要配置安装很多不同的开发框架……还有扩展计算集群……
本次深度学习开发环境调查已经结束,由于样本数量限制,这次我们得出的结论可能不甚准确。深度学习的开发环境会随着技术的发展不断进化,未来究竟是百家争鸣,还是一家独大?欢迎大家前来讨论。感谢大家对机器之心此次调查问卷的支持,获得奖品同学的礼物已经寄出。
Jupyter + Tensorflow + Nvidia GPU + Docker + Google Compute Engine
这一部分,我们编译了一篇新的深度学习开发环境配置:Jupyter + Tensorflow + Nvidia GPU + Docker + Google Compute Engine。
动机:商业上喜欢快捷、且由数据驱动的洞见,因此他们聘请了数据科学家来处理这些任务。实践性的数据科学是探索性、迭代性的过程,这个过程要求大量的计算资源和时间。数据科学家经常使用 Jupyter notebook 以更好地支持这种探索性的迭代,同时更倾向于使用 GPU 以加速 Tensorflow 项目的计算。然而,GPU 成本比较高,而计算资源也需要小心地管理以满足商业上对高效运算的需求。
近来云计算倾向于使用 Kubernetes 和 Docker 提高资源利用率。那数据科学的工具(如 Jupyter 和 GPU 等)嵌入 Docker 和 Kubernets 会更有效吗?也许这样更节约时间和内存,我前面已经用过了其他版本,但现在的环境配置是比较优秀的。
创建一个 GCE 实例

首先,创建防火墙规则,将 Jupyter(8888)和 Tensorboard(6006)添加到白名单中。
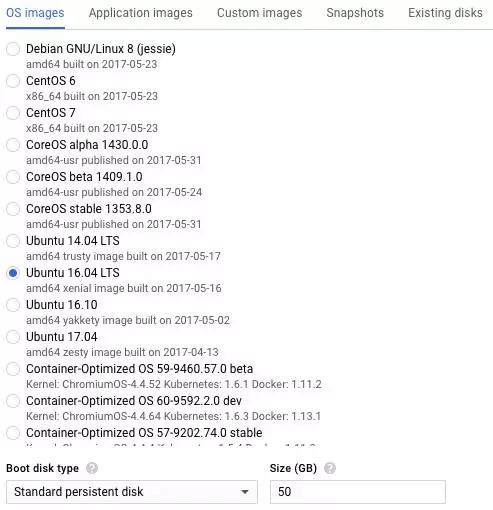
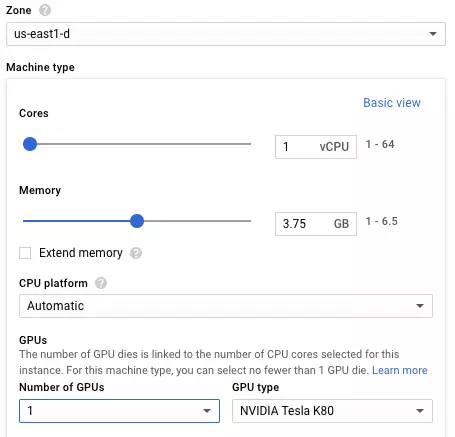
然后创建一个 GCE 实例,对于该案例:
- 使用的系统为 Ubuntu 16.04 LTS
- 分配 50GB 的启动盘
- 至少需要一个 K80 GPU
- 将 jupyter 和 tensorboard添加到你创建的防火墙规则中。
安装和确认 CUDA 能访问 GPU
使用英伟达的 CUDA 库取得访问 GPU 的权限。
下一步需要将 SSH 添加到你创建的计算节点中,然后使用脚本安装 CUDA(https://cloud.google.com/compute/docs/gpus/add-gpus):
_# !/bin/bash
echo "Checking for CUDA and installing."Check for CUDA and try to install.
if ! dpkg-query -W cuda; then
The 16.04 installer works with 16.10.
curl -O http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/cuda-repo-ubuntu1604_8.0.61-1_amd64.deb
dpkg -i ./cuda-repo-ubuntu1604_8.0.61-1amd64.deb
apt-get update
apt-get install cuda -y
fi
然后你能使用 wget 命令 pull 来源 gist 并输入到 bash 中:
wget -O - -q 'https://gist.githubusercontent.com/allenday/f426e0f146d86bfc3dada06eda55e123/raw/41b6d3bc8ab2dfe1e1d09135851c8f11b8dc8db3/install-cuda.sh' | sudo bash
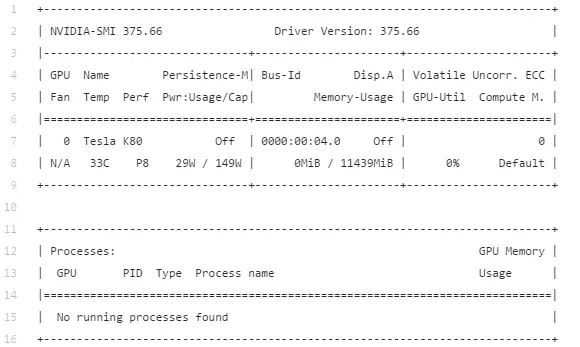
如果 CUDA 安装成功了,运行 nvidia-smi 命令将返回表格显示可用的 Tesla K80 GPU:
nvidia-smi
安装 Docker(-Engine) 和 Nvidia-Docker
对于 docker,我们需要从 Docker 获取 docker-ce 版本,而不是 Ubuntu 自带的 docker.io 包。可以使用以下脚本完成(https://docs.docker.com/engine/installation/linux/ubuntu/)(https://docs.docker.com/engine/installation/linux/ubuntu/%EF%BC%89):
# /bin/bash
# install packages to allow apt to use a repository over HTTPS:
sudo apt-get -y install \
apt-transport-https ca-certificates curl software-properties-common
# add Docker』s official GPG key:
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
# set up the Docker stable repository.
sudo add-apt-repository \
"deb [arch=amd64] https://download.docker.com/linux/ubuntu \
_ $(lsbrelease -cs) \
stable"
# update the apt package index:
sudo apt-get -y update
# finally, install docker
sudo apt-get -y install docker-ce
或使用我的:
wget -O - -q 'https://gist.githubusercontent.com/allenday/c875eaf21a2b416f6478c0a48e428f6a/raw/f7feca1acc1a992afa84f347394fd7e4bfac2599/install-docker-ce.sh' | sudo bash
从 deb 文件安装 nvidia-docker(https://github.com/NVIDIA/nvidia-docker/releases/):
_wget https://github.com/NVIDIA/nvidia-docker/releases/download/v1.0.1/nvidia-docker_1.0.1-1_amd64.deb_
从 Docker 容器确认 GPU 是可用的
起始化 nvidia-docker-plugin 需要在跟权限下运行:
sudo nvidia-docker-plugin &
_nvidia-docker-plugin | 2017/06/07 01:05:05 Loading NVIDIA unified memory___
_nvidia-docker-plugin | 2017/06/07 01:05:05 Loading NVIDIA management library___
_nvidia-docker-plugin | 2017/06/07 01:05:08 Discovering GPU devices___
_nvidia-docker-plugin | 2017/06/07 01:05:08 Provisioning volumes at /var/lib/nvidia-docker/volumes___
_nvidia-docker-plugin | 2017/06/07 01:05:08 Serving plugin API at /run/docker/plugins___
_nvidia-docker-plugin | 2017/06/07 01:05:08 Serving remote API at localhost:3476___
现在确保 docker 容器可以看到 GPU:
sudo nvidia-docker run --rm nvidia/cuda nvidia-smi
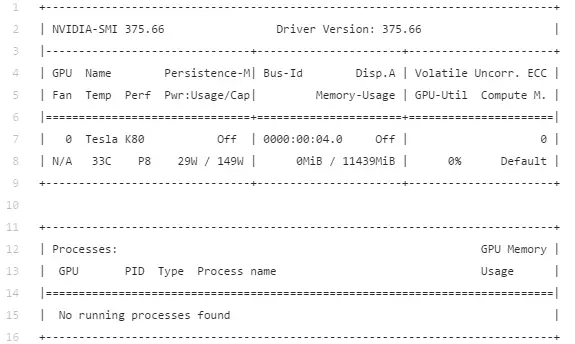
如上图所示,现在得到的表格和前面使用 nvidia-smi 命令,且没有在 Docker 容器里运行得到的表格是一样的。
创建一个 Snapshot 卷
如果你跟着上面运行下来了,你可能注意到它需要花费一点时间。而当我们运行 GPU 实例时,那成本就比较大了。所以我们需要避免重复以上过程浪费时间和内存,我们可以将以上过程做一个整合,当我们需要启动 GPU 时就可以直接使用。
登陆 Jupyter 和 TensorBoard
sudo nvidia-docker run --rm --name tf1 -p 8888:8888 -p 6006:6006 gcr.io/tensorflow/tensorflow:latest-gpu jupyter notebook --allow-root
上面命令可以展示为一个链接:
http://localhost:8888/?token=c8caba947dfd4c97414447c074325faf399cf8a157d0ce2f
最后寻找一个 GCE 实例的外部 IP 地址,并将它连接到端口 8888,即 http://EXTERNAL_IP:8888/,从你的控制台键入类似的符号,现在你就拥有了一个可以在 GPU 上运行 TensorFlow 的 Jupyter notebook。
机器之心整理
参与:李泽南、李亚洲
深度学习, 开发环境
风险提示及免责条款
市场有风险,投资需谨慎。本文不构成个人投资建议,也未考虑到个别用户特殊的投资目标、财务状况或需要。用户应考虑本文中的任何意见、观点或结论是否符合其特定状况。据此投资,责任自负。本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
